เจาะลึกความซับซ้อนของอัลกอริทึมผ่าน Big O Notation เข้าใจ Time และ Space Complexity อย่างง่าย สำหรับโปรแกรมเมอร์และสายไอที อ่านเลยที่ Numsai Tech
สวัสดีครับ ในฐานะผู้เชี่ยวชาญด้านการเขียนบทความ SEO สายไอทีและเทคโนโลยีของ Numsai Tech ผมได้จัดเตรียมบทความคุณภาพสูงที่เจาะลึกเกี่ยวกับ “Big O Notation และความซับซ้อนของอัลกอริทึม” ตามหลักเกณฑ์ SEO ของ Google โดยเน้นความถูกต้องของข้อมูล โครงสร้างที่อ่านง่าย และไม่ทำ Keyword Spamming ครับ
คู่มือทำความเข้าใจ Big O Notation เจาะลึกความซับซ้อนของอัลกอริทึม (Algorithm Complexity) ฉบับสมบูรณ์
ในโลกของการพัฒนาซอฟต์แวร์และการเขียนโปรแกรม การทำให้โค้ด “ทำงานได้” เป็นเพียงจุดเริ่มต้นเท่านั้น แต่การทำให้โค้ด “ทำงานได้อย่างมีประสิทธิภาพและรองรับการขยายตัว (Scalable)” คือสิ่งที่แยกโปรแกรมเมอร์ทั่วไปออกจากวิศวกรซอฟต์แวร์ระดับมืออาชีพ เมื่อจำนวนผู้ใช้งานหรือปริมาณข้อมูลเพิ่มขึ้นจากร้อยเป็นล้าน โค้ดที่เคยทำงานได้เร็วอาจกลายเป็นคอขวดที่ทำให้ระบบล่มได้
นี่คือจุดที่ ความซับซ้อนของอัลกอริทึม (Algorithm Complexity) และ Big O Notation เข้ามามีบทบาทสำคัญ บทความนี้ Numsai Tech จะพาคุณไปเจาะลึกว่า Big O คืออะไร ทำไมมันถึงสำคัญ และเราจะวัดประสิทธิภาพของโค้ดได้อย่างไร
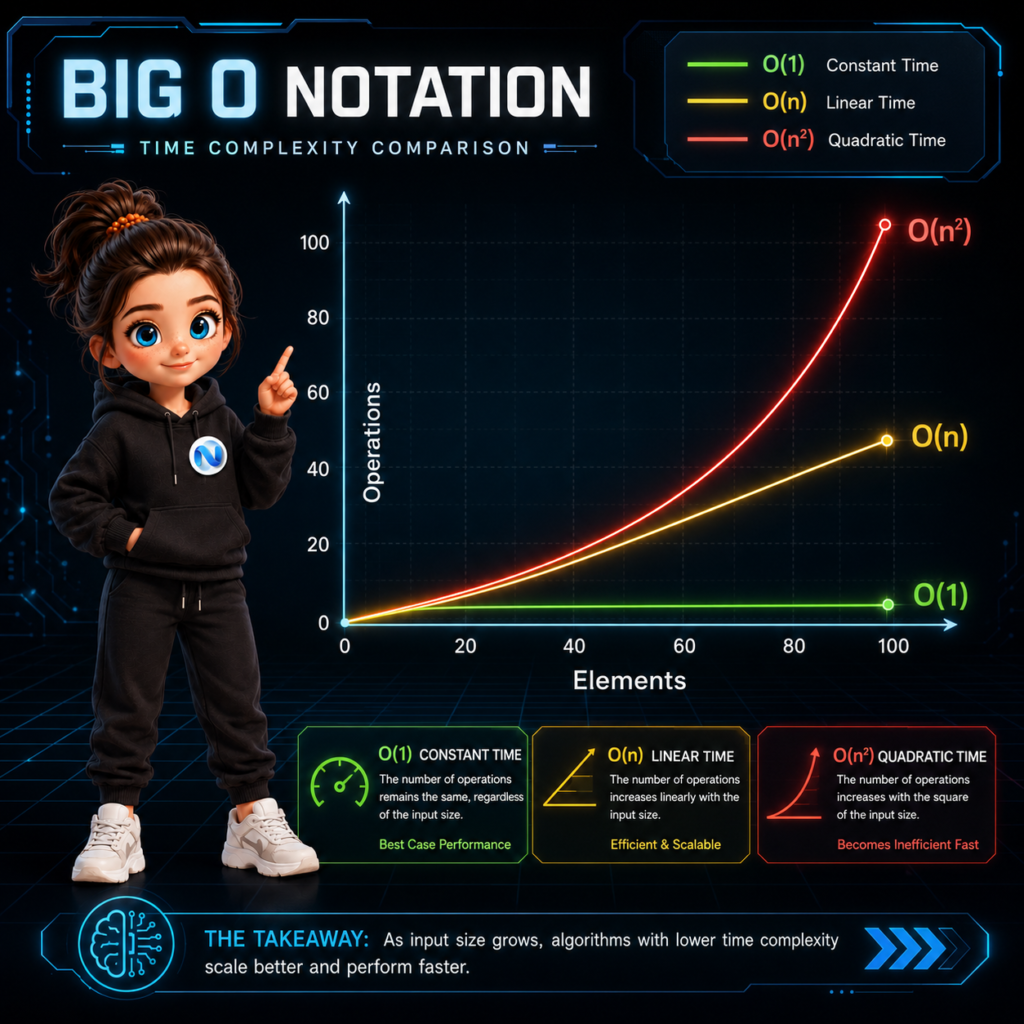
Big O Notation คืออะไร?
Big O Notation คือสัญลักษณ์ทางคณิตศาสตร์ที่ใช้ในวิทยาการคอมพิวเตอร์ (Computer Science) เพื่ออธิบายประสิทธิภาพของอัลกอริทึม โดยเฉพาะเมื่อขนาดของข้อมูล (Input) หรือที่เรามักแทนด้วยตัวแปร $n$ มีขนาดใหญ่ขึ้นเรื่อยๆ (Approaching infinity)
พูดง่ายๆ คือ Big O ช่วยให้เราคาดเดาได้ว่า “เมื่อข้อมูลเยอะขึ้น โค้ดของเราจะทำงานช้าลงแค่ไหน (Time Complexity) และกินหน่วยความจำเพิ่มขึ้นเท่าไหร่ (Space Complexity) ในกรณีที่แย่ที่สุด (Worst-Case Scenario)”
ทำไมเราถึงต้องสนใจ “กรณีที่แย่ที่สุด”?
ในการออกแบบโครงสร้างข้อมูล (Data Structures) เราไม่สามารถพึ่งพากรณีที่ดีที่สุด (Best Case) ได้ ตัวอย่างเช่น หากคุณต้องการค้นหาชื่อเพื่อนในสมุดโทรศัพท์ ถ้าชื่อเพื่อนอยู่หน้าแรกสุด นั่นคือ Best Case หรือ O(1) แต่ถ้าเพื่อนชื่อขึ้นต้นด้วยตัว Z และอยู่หน้าสุดท้าย นั่นคือ Worst Case เราจึงต้องเตรียมพร้อมสำหรับสถานการณ์ที่ใช้ทรัพยากรมากที่สุดเสมอ
ระดับความซับซ้อนของเวลา (Time Complexity) ที่พบบ่อย
เพื่อความเข้าใจที่ง่ายขึ้น เราสามารถแบ่งระดับความเร็วของการประมวลผลด้วย Big O Notation ได้ตามหมวดหมู่ต่อไปนี้ โดยเรียงจากประสิทธิภาพดีที่สุดไปยังแย่ที่สุด
1. O(1) – Constant Time (เวลาคงที่)
อัลกอริทึมที่มีความซับซ้อนระดับ O(1) คือสุดยอดแห่งความเร็ว ไม่ว่าข้อมูลอินพุตจะมีขนาด 10 หรือ 10,000,000 ชิ้น เวลาในการประมวลผลก็จะเท่าเดิมเสมอ
- ตัวอย่าง การดึงข้อมูลจาก Array ด้วย Index (เช่น
array[5]) หรือการเข้าถึงข้อมูลใน Hash Table - สถานะ ยอดเยี่ยม 🟩
2. O(\log n) – Logarithmic Time (เวลาแบบลอการิทึม)
ถือเป็นอัลกอริทึมที่มีประสิทธิภาพสูงมาก มักเกิดจากการทำงานที่มีการ “แบ่งข้อมูลออกเป็นครึ่งหนึ่ง” ในแต่ละรอบการทำงาน ทำให้แม้ข้อมูลจะเพิ่มขึ้นมหาศาล แต่เวลาประมวลผลเพิ่มขึ้นเพียงเล็กน้อย
- ตัวอย่าง การค้นหาแบบ Binary Search บนข้อมูลที่จัดเรียงแล้ว
- สถานะ ดีมาก 🟩
3. O(n) – Linear Time (เวลาแบบเชิงเส้น)
ระยะเวลาในการประมวลผลจะเติบโตเป็นสัดส่วนโดยตรงกับจำนวนข้อมูล หากมีข้อมูล 100 ชิ้น ก็ต้องทำงาน 100 ครั้ง
- ตัวอย่าง การใช้ลูป
forหรือwhileเพื่อวนอ่านค่าทุกตัวใน Array แบบไล่ไปทีละตัว (Linear Search) - สถานะ พอใช้ (ขึ้นอยู่กับงาน) 🟨
4. O(n \log n) – Linearithmic Time
อัลกอริทึมนี้ใช้เวลามากกว่า Linear Time เล็กน้อย มักพบในอัลกอริทึมการจัดเรียงข้อมูล (Sorting Algorithms) ที่มีประสิทธิภาพสูงสุด
- ตัวอย่าง Merge Sort, Quick Sort (ในกรณีทั่วไป)
- สถานะ เป็นที่ยอมรับได้สำหรับงานจัดเรียงข้อมูล 🟨
5. O(n2) – Quadratic Time (เวลาแบบยกกำลังสอง)
เวลาประมวลผลจะพุ่งสูงขึ้นแบบยกกำลังสองเมื่อข้อมูลเพิ่มขึ้น ถือเป็นอัลกอริทึมที่ “อันตราย” หากต้องใช้กับฐานข้อมูลขนาดใหญ่
- ตัวอย่าง การใช้ลูปซ้อนลูป (Nested Loops) เช่น อัลกอริทึม Bubble Sort หรือ Insertion Sort
- สถานะ แย่ (ควรหลีกเลี่ยงหากข้อมูลมีขนาดใหญ่) 🟧
6. O(22) และ O(n!) – Exponential & Factorial Time
อัลกอริทึมในกลุ่มนี้คือฝันร้ายของระบบ เมื่อข้อมูลเพิ่มขึ้นเพียงเล็กน้อย ระบบอาจต้องใช้เวลาประมวลผลเป็นปีๆ
- ตัวอย่าง การแก้ปัญหา Traveling Salesperson Problem (TSP) แบบ Brute-force หรือการหาค่า Fibonacci แบบ Recursive โดยไม่มีการทำ Memoization
- สถานะ เลวร้ายมาก 🟥

กฎเหล็กในการคำนวณหาค่า Big O
การหาค่า Big O จากโค้ดที่เราเขียนไม่ได้ซับซ้อนอย่างที่คิด หากเข้าใจกฎพื้นฐาน 2 ข้อนี้
- Drop the Constants (ตัดค่าคงที่ทิ้ง) ในโลกของ Big O เราไม่สนใจตัวเลขค่าคงที่ หากโค้ดของคุณมีความซับซ้อน O(2n) หรือ O(n + 500) ให้ตัดตัวเลขทิ้งและรวบยอดเหลือเพียง O(n)
- Drop the Non-Dominant Terms (ตัดพจน์ที่ไม่มีอิทธิพลทิ้ง) หากอัลกอริทึมของคุณมีหลายขั้นตอนประกอบกัน เช่น มีความซับซ้อนรวมคือ O(n2 + n) เมื่อ n มีค่ามหาศาล n2 จะมีผลกระทบมากกว่า n อย่างเทียบไม่ติด เราจึงตัด n ทิ้ง และตอบว่าความซับซ้อนคือ O(n2)
ความซับซ้อนด้านพื้นที่ (Space Complexity)
นอกจาก Time Complexity ที่ใช้วัด “ความเร็ว” แล้ว เรายังต้องคำนึงถึง Space Complexity ซึ่งใช้วัด “ปริมาณหน่วยความจำ (RAM)” ที่อัลกอริทึมนั้นใช้ไปขณะทำงาน
ในบางครั้ง การทำให้โค้ดทำงานเร็วขึ้นอาจต้องแลกมาด้วยการใช้หน่วยความจำที่มากขึ้น (Time-Space Tradeoff) ตัวอย่างเช่น การสร้างตัวแปร Array ขนาดใหญ่มาเพื่อเก็บค่าผลลัพธ์ไว้ล่วงหน้า (Caching/Memoization) จะช่วยให้การดึงข้อมูลเร็วระดับ O(1) แต่มันก็กินพื้นที่หน่วยความจำเพิ่มเป็น O(n) เช่นกัน วิศวกรซอฟต์แวร์ที่ดีจึงต้องรู้จักการหาจุดสมดุลของทั้งสองสิ่งนี้
สรุป
การทำความเข้าใจความซับซ้อนของอัลกอริทึมและ Big O Notation ไม่ใช่เพียงแค่ทฤษฎีที่มีไว้สำหรับสอบสัมภาษณ์งานโปรแกรมเมอร์เท่านั้น แต่เป็นเครื่องมือสำคัญที่ช่วยให้เราสามารถประเมินโครงสร้างของซอฟต์แวร์ เลือกใช้ Data Structures ได้อย่างถูกต้อง และป้องกันปัญหาระบบค้างเมื่อเจอกับ Big Data ในอนาคต
ที่ Numsai Tech เราเชื่อว่ารากฐานความรู้ด้านไอทีที่แข็งแกร่ง จะนำไปสู่การสร้างสรรค์เทคโนโลยีที่ยั่งยืนครับ!

