ทำความรู้จัก Hash Table โครงสร้างข้อมูลที่สำคัญที่สุดในวิทยาการคอมพิวเตอร์ เจาะลึกการทำงานของ Hash Function, การจัดการ Collision และเหตุผลที่ค้นหาข้อมูลได้ใน O(1)

Hash Table คืออะไร? เจาะลึกโครงสร้างข้อมูลที่ค้นหาได้เร็วที่สุด O(1)
ในโลกของวิทยาการคอมพิวเตอร์และการพัฒนาซอฟต์แวร์ การจัดการกับข้อมูลปริมาณมหาศาล (Big Data) ถือเป็นความท้าทายระดับชาติของโปรแกรมเมอร์ ไม่ว่าคุณจะสร้างแอปพลิเคชันธรรมดา หรือระบบเครือข่ายคอมพิวเตอร์ขั้นสูง สิ่งหนึ่งที่ชี้วัดประสิทธิภาพของระบบคือ “ความเร็วในการค้นหาข้อมูล”
หากคุณต้องการดึงข้อมูลหนึ่งชิ้นจากข้อมูลนับล้านเรคคอร์ดในเสี้ยววินาที โครงสร้างข้อมูลที่ชื่อว่า Hash Table (แฮชเทเบิล) คือคำตอบที่บริษัทไอทียักษ์ใหญ่ทั่วโลกเลือกใช้ บทความนี้จาก numsai.com จะพาทุกท่านไปเจาะลึกการทำงานของโครงสร้างข้อมูลตัวนี้กันครับ
📌 Hash Table คืออะไร?
Hash Table (บางภาษาเรียกว่า Dictionary, Map หรือ Associative Array) คือโครงสร้างข้อมูล (Data Structure) ที่ใช้สำหรับจัดเก็บข้อมูลในรูปแบบคู่ของ คีย์และค่า (Key-Value Pair)
เปรียบเทียบง่ายๆ เหมือนกับระบบของ “พจนานุกรม” หากคุณต้องการหาความหมายของคำว่า “Network” (นี่คือ Key) คุณไม่จำเป็นต้องอ่านหนังสือตั้งแต่หน้าแรกเพื่อหาคำๆ นี้ แต่คุณสามารถเปิดไปที่หมวดตัวอักษร ‘N’ และค้นหาจนเจอความหมาย (นี่คือ Value) ได้อย่างรวดเร็ว
จุดเด่นที่สุดที่ทำให้ Hash Table เป็นราชาแห่งโครงสร้างข้อมูลคือ Time Complexity (ความซับซ้อนของเวลา) ในการเพิ่มข้อมูล (Insert), ลบข้อมูล (Delete) และค้นหาข้อมูล (Search) จะใช้เวลาเฉลี่ยเพียง O(1) หรือคงที่เสมอ ไม่ว่าข้อมูลจะมีขนาด 10 ชิ้น หรือ 100 ล้านชิ้นก็ตาม
⚙️ องค์ประกอบหลักของ Hash Table
การทำงานที่รวดเร็วของ Hash Table นั้น อาศัยส่วนประกอบสำคัญ 3 ส่วนที่ทำงานประสานกันอย่างเป็นระบบ ดังนี้
1. Key (คีย์)
คีย์คือตัวแปรที่เราใช้สำหรับอ้างอิงเพื่อเข้าถึงข้อมูล คีย์จะต้องมีคุณสมบัติที่ ไม่ซ้ำกัน (Unique) เช่น รหัสพนักงาน, หมายเลขบัตรประชาชน, ไอพีแอดเดรส (IP Address) หรืออีเมลผู้ใช้งาน
2. Hash Function (ฟังก์ชันแฮช)
ฟังก์ชันแฮชคือ “สมองกล” ของ Hash Table มันคืออัลกอริทึมทางคณิตศาสตร์ที่ทำหน้าที่รับ Key เข้ามาประมวลผล แล้วแปลงสภาพให้กลายเป็น ตัวเลขจำนวนเต็ม (Integer) ซึ่งเราเรียกตัวเลขนี้ว่า Hash Code หรือ Index
คุณสมบัติของ Hash Function ที่ดีตามหลักวิศวกรรมซอฟต์แวร์มีดังนี้
- Deterministic หากใส่ Key เดิมเข้าไป จะต้องคำนวณได้ Hash Code ตัวเดิมเสมอ
- Uniformity ต้องกระจายข้อมูลลงในพื้นที่จัดเก็บได้อย่างสม่ำเสมอ เพื่อลดอัตราการชนกัน (Collision)
- Fast Computation ต้องคำนวณได้อย่างรวดเร็ว ไม่ซับซ้อนจนกินทรัพยากรซีพียู
3. Buckets / Array (พื้นที่จัดเก็บ)
คือโครงสร้างข้อมูลประเภท Array ที่อยู่เบื้องหลัง Hash Table โดยตัวเลข Index ที่คำนวณได้จาก Hash Function จะถูกนำมาใช้เป็น “ตำแหน่ง” ของ Array ว่าเราจะนำ Value ไปจัดเก็บไว้ที่ช่องใด
🚀 กลไกการทำงานเบื้องหลัง ทำไมถึงเร็วระดับ O(1)?
เพื่อแสดงให้เห็นภาพชัดเจน เรามาเปรียบเทียบความเร็วในการค้นหาข้อมูลกันครับ สมมติว่าเรามีฐานข้อมูลผู้ใช้งาน 1,000,000 คน
- การค้นหาแบบปกติ (Linear Search) หากต้องการหาข้อมูลของ “สมชาย” ระบบจะเริ่มตรวจสอบตั้งแต่ Index ที่ 0, 1, 2… ไปเรื่อยๆ หากสมชายอยู่คนสุดท้าย ระบบต้องทำการตรวจสอบถึง 1 ล้านครั้ง ความซับซ้อนคือ O(N)
- การค้นหาด้วย Hash Table ระบบจะนำชื่อ “สมชาย” (Key) ไปผ่าน Hash Function ระบบคำนวณปุ๊บได้ตัวเลข Index ออกมาเป็น
845,002คอมพิวเตอร์จึงข้ามไปดึงข้อมูลที่ Array ตำแหน่ง845,002ได้ทันที การดำเนินการนี้ใช้การคำนวณเพียง 1 ครั้ง ความซับซ้อนจึงเป็น O(1)
💥 การรับมือกับปัญหา Hash Collision
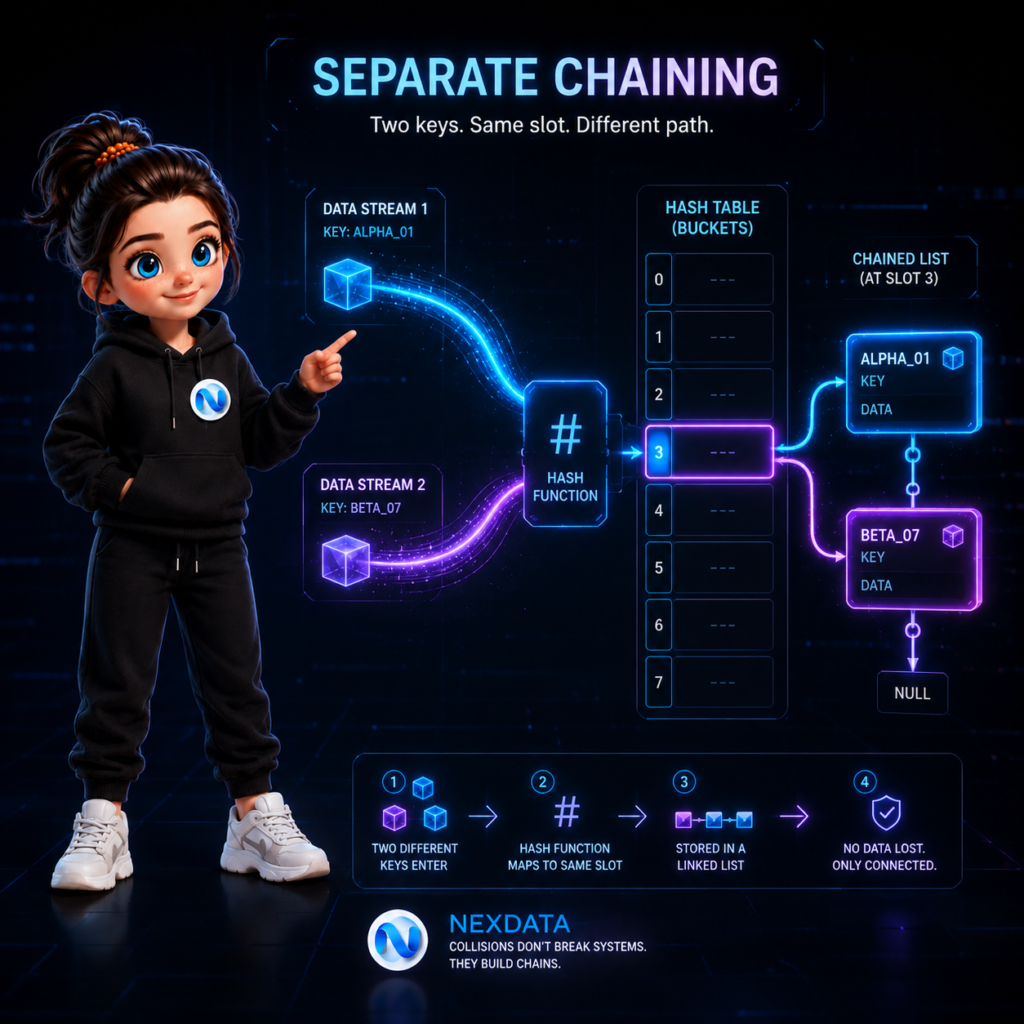
แม้ในทางทฤษฎีจะดูสมบูรณ์แบบ แต่ในโลกของการเขียนโปรแกรมจริง เราต้องเผชิญกับสิ่งที่เรียกว่า Hash Collision (การชนกันของแฮช)
การชนกันเกิดขึ้นเมื่อ Key 2 ตัวที่ต่างกัน แต่ Hash Function ดันคำนวณค่า Index ออกมาได้เป็นตัวเลขเดียวกันพอดี เมื่อเกิดเหตุการณ์นี้ขึ้น ระบบจะมีวิธีจัดการมาตรฐานอยู่ 2 รูปแบบหลัก
ตารางเปรียบเทียบวิธีจัดการ Collision
| วิธีการจัดการ (Method) | อธิบายหลักการทำงาน | ข้อดี / ข้อเสีย |
| Separate Chaining | เปลี่ยนแต่ละช่องของ Array ให้เก็บข้อมูลเป็นแบบ Linked List หากมีข้อมูลตกช่องเดียวกันก็นำไปต่อท้ายเป็นสายโซ่ | ข้อดี จัดการง่าย, รองรับข้อมูลได้ไม่จำกัด (ขึ้นอยู่กับ RAM) ข้อเสีย เปลืองหน่วยความจำเพิ่มเติม |
| Open Addressing | หากช่องนั้นมีข้อมูลอยู่แล้ว ระบบจะเลื่อนไปหา “ช่องว่างถัดไป” ใน Array ตามสมการที่กำหนด (เช่น Linear Probing) | ข้อดี ประหยัด Memory เพราะไม่ต้องสร้าง Pointer เหมือน Linked List ข้อเสีย หากข้อมูลแน่นเกินไป ประสิทธิภาพจะลดลงฮวบฮาบ |
🌐 การประยุกต์ใช้งานในสายเทคโนโลยีและไอที
โครงสร้างข้อมูล Hash Table ไม่ได้เป็นเพียงทฤษฎีในห้องเรียน Computer Science แต่ถูกนำมาใช้งานจริงในระบบสเกลระดับโลก ดังนี้:
- ระบบแคช (Caching Systems) ซอฟต์แวร์ด้านประสิทธิภาพอย่าง Redis หรือ Memcached ใช้แนวคิด Key-Value Store บนหน่วยความจำ (RAM) เพื่อให้เว็บแอปพลิเคชันดึงข้อมูลที่ใช้บ่อยได้อย่างรวดเร็ว
- ดัชนีฐานข้อมูล (Database Indexing) แม้ฐานข้อมูลส่วนใหญ่จะใช้ B-Tree ในการทำ Index แต่ในกรณีที่ต้องการเข้าถึงข้อมูลแบบระบุตัวตนเป๊ะๆ (Exact Match) การใช้ Hash Index จะทรงประสิทธิภาพที่สุด
- การจัดการ Routing ในเครือข่าย อุปกรณ์ฮาร์ดแวร์เครือข่ายขั้นสูง เช่น Router หรือ Switch ระดับ Enterprise ใช้โครงสร้างแบบ Hash เพื่อจดจำและค้นหา MAC Address และ IP Address ใน Routing Table ทำให้ส่งแพ็กเก็ตข้อมูลได้รวดเร็ว
- วิทยาการความปลอดภัยไซเบอร์ (Cybersecurity) ต่อยอดเป็นกระบวนการเข้ารหัส (Cryptographic Hash) เช่น SHA-256 เพื่อตรวจสอบความถูกต้องของไฟล์ข้อมูล (Data Integrity) หรือใช้ในการจัดเก็บรหัสผ่าน (Password Hashing) อย่างปลอดภัย
🎯 บทสรุปส่งท้าย
Hash Table ถือเป็นสิ่งประดิษฐ์ทางโครงสร้างข้อมูลที่เปลี่ยนโฉมหน้าการเขียนโปรแกรมไปตลอดกาล ด้วยความสามารถในการเข้าถึงข้อมูลได้อย่างฉับไวในเวลาคงที่ O(1) ทำให้ระบบไอทีและซอฟต์แวร์ระดับองค์กรสามารถรองรับผู้ใช้งานพร้อมกันจำนวนมหาศาลได้โดยที่ระบบไม่ล่ม
สำหรับนักพัฒนาซอฟต์แวร์และโปรแกรมเมอร์ การทำความเข้าใจโครงสร้างข้อมูลตัวนี้อย่างถ่องแท้ ไม่ว่าจะเป็นเรื่องของ Hash Function หรือการจัดการ Collision ล้วนเป็นรากฐานสำคัญที่จะช่วยให้คุณออกแบบระบบที่ทั้ง “รวดเร็ว” และ “ปลอดภัย” ได้อย่างมีประสิทธิภาพสูงสุดครับ
หากคุณชื่นชอบเนื้อหาเชิงลึกสายไอที ซอฟต์แวร์ และเทคโนโลยีแบบนี้ อย่าลืมติดตามบทความใหม่ๆ จาก numsai.com เพื่ออัปเดตความรู้ในโลกดิจิทัลไปพร้อมกันครับ!





